
微信课堂:化解控制文件归档日志查询缓慢及ASM执行计划一则
作者:盖国强(Eygle)
在我们的技术讨论群『云和恩墨大讲堂』中,还有日常的微信互动中,经常有朋友会提出一些有趣的小问题,在空闲的时候,我希望能够记录下来,和大家做一点小分享,以点滴的知识,增进一点点对于Oracle的理解,就名之为『微信课堂』吧。
归档查询与控制文件
最近有朋友在『云和恩墨大讲堂』微信群里提出了一个问题:
查询 v$archive_gap 会进入一个漫长的 control file sequential read 的等待事件,查询起码半小时。
这大概怎么排查?v$controlfile_record_section也看了,log history有37376条记录。
其实这是一个常见现象,由于归档日志信息记录在控制文件中,很多和归档相关的操作最终都要从控制文件获取信息,而控制文件很有可能因为重复写入而产生碎片、扩展,导致这个过程非常缓慢。
怎么解决这个问题呢?
如果通过 crosscheck 等正常操作无法清理信息和解决问题,那么最后还有一个办法,用 dbms_backup_restore.resetcfilesection 将控制文件中,存储归档日志信息部分清空,就彻底解决问题了(注意:在生产上使用需要非常谨慎和经过测试,并确保控制文件相应部分的信息不再需要)。
以下命令就是清理控制文件中 11 部分(通过 v$controlfile_record_section 可以获得详细信息),这部分就是归档信息:
SQL>execute sys.dbms_backup_restore.resetCfileSection( 11);
如果清理之后,你还想把正常的归档日志加入进来,可以通过如下的命令实现:
RMAN> catalog start with '/u01/archives';
但是注意,dbms_backup_restore 的功能非常强大,值得深入去学习和研究。
在 $ORACLE_HOME/rdbms/admin/dbmsbkrs.sql 文件中,可以找到这个程序文件,其中关于 Section 的记录如下:
当数据库变大之后,控制文件上也会出现有意思的情形,Oracle 数据库值得注意的细节也无处不在。
那么,还有同学问,如何直观的去看到这些信息呢?其实在Oracle数据库中可以通过转储事件( controlf ),将控制文件中的二进制信息转化成文本格式输出,就可以一目了然的阅读控制文件中存储的内容:
SQL> alter session set events 'immediate trace name controlf level 8';
Session altered.
SQL> select value from v$diag_info where name like '%Tra%';
VALUE
——————————————————————————–
/u01/CLOUD/trace/CLOUD_ora_20361.trc
在原文链接中,你可以在我的网站上找到一个示范。
ASM 视图查询与优化器
最近有一个做产品的朋友提出一个问题,以下这条SQL在某个用户环境下执行非常缓慢,影响到了产品的正常工作,需要分析一下其原因并解决执行缓慢的SQL问题:
SQL> SELECT g.group_number,
2 f.number_kffil
3 FROM v$asm_diskgroup g, x$kffil f, v$asm_alias a
4 WHERE g.group_number=f.group_kffil
5 AND g.group_number=a.group_number
6 AND f.number_kffil=a.file_number;
这条SQL中引用了一个大家可能不太熟悉的 X$ 固定表: X$KFFIL ,这个视图用于列出ASM文件,包括 元数据/ASMDISK 文件,KFF 的含义是Kernel File,v$asm_file 视图就是建立于 X$KFFIL 之上。
另外一个ASM至关重要的固定表是 X$KFFXP,其含义是 即Kernel File Extent Maps,该视图反应 File Extent Map 映射关系,其中的一条记录代表一个Extent。
在朋友给出的执行计划中,我注意到其中一行信息提示『当前数据库使用的是RBO优化器』,虽然这是一个11.2.0.4的数据库环境:
Note
—–
– rule based optimizer used (consider using cbo)
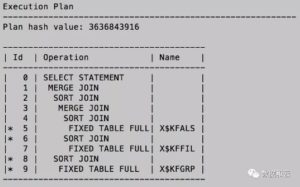
在RBO下,这条SQL的执行计划如下,我们注意到 MERGE JOIN 是其中主要的执行方式,当其中某些表数据量较大时,这个执行计划可能不理想:
显然,这也是客户现场遇到的问题原因,RBO 选择了一个不优的执行计划。
通过这个案例,我们需要认识到:
RBO 已经属于过时的优化器,应当尽可能的放弃;
RBO 可能使某些数据库系统对象查询效率降低,导致数据库的核心功能工作不正常;
那么如何让这个SQL获得更优的执行计划,表现的正常一点呢?
我们可以确定一下在CBO下其正常的执行计划,并对其进行引导,一个 hints 可能就能够趋势其使用高效率一点的执行计划:
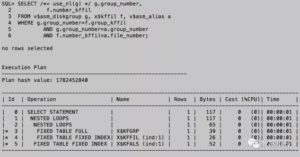
如果驱动表的记录数很少,NL 就能够更高效率的返回结果,以上的执行计划就优于前者,如果对比一下正常的环境效率,就可以让SQL回归正确的执行方式。
欢迎大家为我们投稿,分享你的经验!
更多精彩关注“数据和云”公众号