—-曾令军,云和恩墨南区交付技术经理
堵塞往往是一件可怕的事情,交通堵塞让人心烦意乱,水道堵塞城市就会臭气冲天,言路堵塞则是非难辨。数据库出现会话堵塞,则很可能造成系统业务中断,这对于DBA来说,是一个非常大的考验。幸运的是,Oracle数据库产品非常成熟,有完善的日志体系、运行数据跟踪记录、全面的数据字典,可以帮助我们在遇到问题时,有迹可循有据可查。在处理这类问题时,在千头万绪的会话和数据中,理清思路正本清源,从根本上治理堵塞的问题是最重要的,这也是本文想要阐述的一个核心观点:洞若观火–治堵之道在清源。
理论容易理解,却难于上手使用,实战才是最好的老师。我们从一个案例入手,将会话堵塞问题相关的数据库基础知识与实战方法嵌入其中,一起探寻治堵的乐趣。
1.观察:把问题说清楚
在我印象中,DBA都是很明事理的人,因为这个职业经常要干的一件事情就是:“把问题说清楚,把规矩讲明白”。这是一项软技能,不管是问题分析过程中与同行沟通,还是最后给领导汇报,清楚明白是基本的要求。关于会话堵塞要说清楚的几个问题:
- 会话增长趋势是怎样的?
- 有没有等待事件?
- 服务器资源消耗情况怎样?
- 对业务的影响范围多大?
1.1. 会话的增长趋势
进入案例,查询V$SYSMETRIC_HISTORY视图,可以得出每分钟内会话数的增长趋势:
select begin_time,trunc(value) from V$SYSMETRIC_HISTORY where metric_name='Average Active Sessions' and group_id=2 order by begin_time;
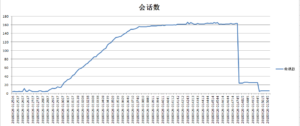
从6月26日01:28分开始,节点1的活动会话数突增,从平常的10左右增加到近160个活动会话,持续到01:50分左右恢复正常。
1.2. 等待事件情况
查询v$active_session_history视图(数据保留时间有限,没有就查历史视图),分析问题开始时间段的等待事件情况:
select trunc(sample_time,'mi'),event,count(1) from dba_hist_active_sess_history
where SAMPLE_TIME>to_date('20180626 01:26:00','yyyymmdd hh24:mi:ss')
and SAMPLE_TIME<to_date('20180626 01:31:00','yyyymmdd hh24:mi:ss') and event is not null group by trunc(sample_time,'mi'),event having count(1)>2 order by 1,3;
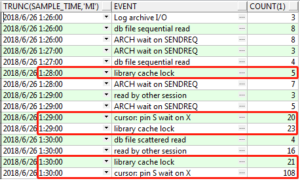
数据库中的等待事件通常都会很多,哪些才是与问题有关的,甄别技巧有两个:
- 哪些是新出现的等待事件
- 哪些是数量越来越多的等待事件
比如上图,首先从1:28分,出现library cache lock等待事件,接着在1:29分出现cursor:pin S wait on X等待事件及library cache lock,然后在1:30分开始,等待阻塞就更加严重了,主要的表现还是library cache lock伴随着cursor: pin S wait on X。那么library cache lock就是需要重点分析的事件。
服务器的资源消耗情况、业务的影响范围,这两部分数据也是需要了解的,比较简单此处没有贴出。问题现象已经明白了:
- 数据库1:28分开始出现会话阻塞,增长速度很快
- 阻塞时伴随着严重的library cache lock等待事件
2.分析:找到源头是关键
阻塞问题有一个共同特点:最开始都是小规模的等待,然后不断有更多的会话产生级联等待。从第一部分的现象描述中,我们已经得出信息:01:28分,出现library cache lock等待事件。沿着这条线索,继续分析ASH视图数据:

在1:28分问题刚开始的阶段,等待library cache lock的SQL语句有:31m8x89zjtfxu、b0gj1rx574uhb、c0a2qqsna22ta及33c1zf5v6t8t3,其中两个会话执行33c1zf5v6t8t3是建索引的语句,另外三个,一个是查询,一个是插入、一个是update语句,这三个语句都是在进行解析操作,等待事件都是library cache lock。
2.1. 等待事件说明
根据MOS 'library cache lock' Waits: Causes and Solutions (文档 ID 1952395.1) 文档描述我们得知,在对相关表进行DDL操作的时候,依赖于这个对象的游标会失效,导致大量的硬解析,存储过程、包或者视图失效进行重编译,而在编译的过程当中会加独占锁,而且SQL语句在解析的时候会申请library cache lock来锁定对象,如果相关对象在重编译、或者别的会话正在解析相同的语句,就获取不到锁资源,产生等待。
When objects (like tables or views) are altered via DDL or collecting statistics, the cursors that depend on them are invalidated. This will cause the cursor to be hard parsed when it is executed again and will impact CPU and latches. DDL will often cause library cache objects to be invalidated and this could cascade to many different dependent objects like cursors. Invalidations have a large impact on the library cache, shared pool, row cache, and CPU since they will likely require many hard parses to occur at the same time.
Effort Details : Low effort; defer the DDL to a quiet time. Solution Implementation Not Applicable. Simply schedule DDL during maintenance or low activity periods. |
2.2. 等待事件与SQL
这个等待是与SQL解析有关,首先抓取到这些被阻塞的SQL语句文本(涉及到客户信息,只截取部分SQL):
b0gj1rx574uhb
|
INSERT INTO KTP_ACQR (。。。。。。) SELECT T.* FROM (SELECT 。。。。。。 FROM KNA_ACCS A JOIN KNA_DPAC B ON B.ACCTID = A.ACCTID AND B.DEBTTP = 'xxx' JOIN KNA_ACCS C ON C.ACCTID = B.ACCTID JOIN H_KNS_TRAN D ON D.TRANDT = B.OPENDT AND D.TRANSQ = B.OPTRSQ JOIN KNC_ACID E ON E.DATAVL = C.ACCTNO JOIN CIF_CERT F ON F.CUSTNO = E.CUSTNO WHERE A.ACCTNO = xxx |
c0a2qqsna22ta
|
UPDATE KTP_BILL A SET (A.ACCTID, A.NOTCTG, A.SERVTP) = (SELECT B.PRCSCD, B.TRANST, B.SERVTP FROM H_KNS_TRAN B WHERE A.TRANDT = B.TRANDT AND A.TRANSQ = B.TRANSQ) |
另外还有两个创建索引的会话33c1zf5v6t8t3,可以看出,这些SQL以及创建索引的操作都与H_KNS_TRAN有关
2.3. 数据库日志分析
结合上述两个部分的分析过程,library cache lock等待事件很可能是由于与H_KNS_TRAN有关的DDL语句引起,此时我们去检查数据库日志进行确认,是否存在与H_KNS_TRAN有关的DDL操作:
|
Tue Jun 26 01:28:38 2018 …….省略部分 create table H_KNS_TRAN_mid tablespace cbmain_hist as select * from H_KNS_TRAN where 1=2 Some indexes or index [sub]partitions of table H_KNS_TRAN have been marked unusable alter table H_KNS_TRAN exchange partition p20170625 with table H_KNS_TRAN_mid alter table H_KNS_TRAN_CLS split PARTITION pever AT ('20170626') INTO (PARTITION P20170625, PARTITION pever) alter table H_KNS_TRAN_CLS exchange partition P20170625 with table H_KNS_TRAN_mid drop table H_KNS_TRAN_mid alter table H_KNS_TRAN drop partition P20170625 Some indexes or index [sub]partitions of table H_KNS_TRAN have been marked unusable alter table H_KNS_TRAN split PARTITION pever values ('20180625') INTO(PARTITION P20180625, PARTITION pever) |
通过数据库日志,我们发现,在删除分区操作之后,数据库有提示索引失效的问题,并接下来还进行了split分区的操作。DDL操作必然会导致相关对象的游标失效,索引失效,进而出现大量的library cache lock等待事件。数据库做删除分区操作时,也会导致全局索引失效,这个问题在MOS文档Top Issues Encountered Regarding Split Partition (文档 ID 199623.1)有详细描述,除非split的分区表没有数据,否则SPLIT分区表的操作会导致新的分区索引失效。
|
4. What happens to the indexes when a SPLIT command is issued? Unless the partition you are splitting does not contain any data, indexes are marked UNUSABLE as explained below: For non-Index Organized table : -Oracle marks UNUSABLE the new partitions in each local index. For an IOT table: -Oracle marks UNUSABLE the new partitions in each local index. The ALTER INDEX REBUILD PARTITION statement can be used to regenerate a single partition in a local or global partitioned index. This saves you from having Splitting Partitions: How To Specify Tablespaces For Index Partitions (Doc ID 1524948.1)
|
检查h_kns_tran表的索引情况,确实存在一个全局索引,而且这个全局索引每天晚上都会重建,但是由于这个索引用的并不多,而且表上还有另外一个PK主键索引,所以对系统的冲击并不大。
从这部分的分析可以得出,最根本的原因就是这些DDL操作,引起了数据库中大量的游标失效,以及索引失效,SQL需要重新硬解析,硬解析又引起了会话阻塞。但是问题来了,这些DDL操作的用途是做历史数据转移,从应用的角度来说,是不可缺少的。注意到当时处于凌晨,并发的业务量并不大。所以,还需要进一步分析阻塞的源头,以及硬解析的具体情况。
2.4. 阻塞源头分析
前面的内容都是准备阶段和分析的前奏,这部分进入了本文档最重要的环节:找源头。
第一步:找blocking_session
select sample_time,session_id,sql_id,sql_opname,event,blocking_session,blocking_session_serial# from dba_hist_active_sess_history
where SAMPLE_TIME>to_date('20180626 1:26:00','yyyymmdd hh24:mi:ss')
and SAMPLE_TIME<to_date('20180626 1:31:00','yyyymmdd hh24:mi:ss')
and event='library cache lock'
order by sample_time;
从时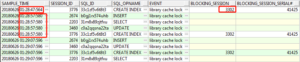 间线上分析,会话最早是在1:28:47秒出现阻塞,1:28:57秒这个时刻被阻塞的4个会话都是后续串连发生的。由该信息可以推断,会话3302是其他会话发生library cache lock的源头, 正在执行的语句为cc2zqqrwy84c1,这条语句也是涉及到对象H_KNS_TRAN这个视图。
间线上分析,会话最早是在1:28:47秒出现阻塞,1:28:57秒这个时刻被阻塞的4个会话都是后续串连发生的。由该信息可以推断,会话3302是其他会话发生library cache lock的源头, 正在执行的语句为cc2zqqrwy84c1,这条语句也是涉及到对象H_KNS_TRAN这个视图。
|
UPDATE KTP_BILL A SET (CORRTG, SERVTP) = (SELECT TRANST, SERVTP FROM H_KNS_TRAN B WHERE A.TRANDT = B.TRANDT AND A.TRANSQ = B.TRANSQ) |
第二步:分析blocking_session的运行轨迹
进一步分析该3302这个会话在问题26分到30分之间(时间范围略有放大,是为了确保开始时间的准确性)的执行情况:
select sample_time,session_id,session_serial#,sql_id,in_parse,in_hard_parse,event,p1,p2,p3,blocking_session from dba_hist_active_sess_history where session_id=3302 and session_serial#=41425 and SAMPLE_TIME>to_date('20180626 01:26:00','yyyymmdd hh24:mi:ss') and SAMPLE_TIME<to_date('20180626 01:31:00','yyyymmdd hh24:mi:ss')
order by sample_time;
![]()
从这个会话的执行情况及等待事件的轨迹数据,可以得到以下几点信息:
- 01:28:47秒到01:29:47秒之间,该会话一直卡在cc2zqqrwy84c1这条SQL语句上,共持续了60多秒。
- cc2zqqrwy84c1前60秒都处于In_hard_parse(硬解析)的状态,这两个字段很多人没有留意,其实对分析解析的问题非常有用。注意这个系统中设置了超时时间,如果交易60秒内不能完成,就会被强制回滚。所以从29:37秒,会话采样到的信息为读取1号system.dbf数据文件(p1参数),其实就是读了回滚段
- 分析该SQL前60秒(硬解析过程中)的P1、P2参数,对应dba_extents视图的段信息:
select * from dba_extents where file_id=72 and (3521740 between block_id and block_id+blocks)
(结果图略)查询到的结果显示会话一直在读取H_KNS_TRAN这个表,从2017年的分区数据一直读到2018年的分区数据。
注意这里的等待事件是db file sequential read,数据文件单块读。问题来了,解析过程为什么会有单块读呢,而且是读表数据,不是索引或数据字典之类的数据?
第三步:推测最终的原因
大量表数据的单块读,只有一种情况,那就是数据动态采样。由于这条语句最终没有解析成功,从数据库中找出一条与该语句类似的SQL,通过下面这条SQL语句查询确认:
select * from table(dbms_xplan.display_awr('cc2zqqrwy84c1'));
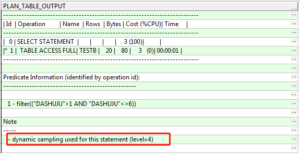
上图为模拟示例图,生成执行计划时,确实存在动态采样的情况,采样级别为level 4。同时检查数据库optimizer_dynamic_sampling参数,值也是4,也就是说引发阻塞的这60秒的时间,都是在对h_kns_tran表进行动态采样。而在这个采样的过程中,一直是持有该表上的解析相关的锁资源的,所以才引发了后面的大量library cache lock的等待。
2.5. 扩展知识
这里需要了解一个知识点,动态采样技术可以通过直接从需要分析的对象上收集数据块(采样)来获得CBO需要的统计信息,分成了11个级别,具体参考官方文档:Table 13-10 Dynamic Statistics Levels。Level 2是默认值,对所有的未分析表做分析,动态采样的数据块是默认数据块数为64;而Level 4采样的表包含满足Level 2和Level 3定义的表,同时还包括单表的谓词会引用另外的2个列或者更多的列。大多数SQL都会存在2个或更多列的谓词条件,所以这个范围是非常大的。如果数据库的动态采样级别设置为4,在稍微大点的表相关SQL进行硬解析的时候,很可能会触发动态采样,这在SQL执行频率特别高的OLTP系统中,是不恰当的。
总算找到了问题的根本原因,将动态采样级别降回到默认值之后,堵塞的问题就没有再发生了。找到根源,排除堵塞源头,是解决问题的关键。
3.总结:思路决定出路
不论是解决小的数据库问题,还是做大型的专项工作,思路起到了决定成败的作用。在运维工作过程中,这需要我们不断地总结和积累,把自己实战的经历、领悟到的技巧,转换成做实事的思路和经验。
对于这次问题来说,把问题说清楚并不难:
- 最根本的原因是程序中存在对大表的DDL操作,引发了索引失效和游标失效
- 索引失效和游标失效会引起SQL硬解析
- SQL硬解析时发生了大表的动态采样,长时间持有锁资源,进而导致了会话阻塞现象的发生
更进一步,我们需要对这一类问题的处理思路做出总结:
- 把问题说清楚,充分了解问题现象、时间范围、影响范围
- 从源头入手,找到开始的时间,理清问题发生的脉络
- 以时间为线索,重点分析阻塞会话的运行轨迹和ASH数据
- 理论知识扎实,对看到的数据才具备敏感性
- 充分利用MOS和官方文档等资料,协助分析,很多时候都是现学现用
更多精彩请关注“数据和云”公众号